Народное достояние Рунета
Скачивание и восстановление сайтов
Спасение сайтов - это кропотливая работа. Первым делом сайт скачивается с помощью программ Teleport Pro или Wget.
Дальнейшие действия зависят от того, с какого бесплатного хостинга был скачан сайт. Сайту, скачанному с narod.yandex.ru (Яндекс.Народ) (домены вида site.narod.ru), потребуется очистка каждой HTML-страницы от рекламного кода, добавленного новым владельцем Народа - хостинг-провайдером UCOZ.
Рекламный код может быть вставлен выше тега <html> и (или) в содержимое тега-контейнера <head> … </head>.
Смело удаляйте строки следующего вида:
В особенности подключаемые JavaScript с внешними ссылками вроде:
<script type="text/javascript" src="http://s206.ucoz.net/"></script>
Если в JavaScript скриптах, размещенных прямо на странице, <script type="text/javascript"> … </script> встречается что-то со словом UCOZ, тоже удаляйте. Полностью, включая открывающий и закрывающий теги.
В эпоху Web 1.0 при создании сайтов использование JavaScript библиотек не носило массовый характер. Это важно учитывать. JavaScript использовался и тогда, но это были простые скрипты. К сожалению, нету простого способа, как отличить нужный скрипт от рекламного. Тут потребуются базовые знания JavaScript и опыт.
Также в самом конце страницы может попасться gif-картинка с надписью вроде "hosted by ucoz", "основано на технологиях UCOZ", "сайт управляется системой UCOZ" и т.д. Тоже смело удаляйте следующий код типа:
<!-- copyright (i5) --><div align="center"><a href="http://www.ucoz.ru/" title="Создать сайт бесплатно"><img style="margin:0;padding:0;border:0;" alt="Hosted by uCoz" src="http://s206.ucoz.net/img/cp/9.gif" width="80" height="15" title="Hosted by uCoz" /></a><br /></div><!-- /copyright -->
Если попадётся строчка в стиле "купить насосы недорого http://takoytosait.ru" - тоже ее удалите. Также удаляем скрипты счётчиков Narod.Ru, Top.Mail.Ru, LiveInternet.Ru и т.д. и т.п.
Очистив все html страницы от рекламных скриптов. Половина дела сделана. Следующий этап - проверка внутренних ссылок. Особое внимание обратите на регистры букв. Помните об регистрозависимости ссылок. page.html и Page.html – это разные файлы. Если возможно – делаем все ссылки строчными (малыми) буквами. Не забываем также поступить с названиями файлов. Удалённые UCOZом страницы и файлы ищите при помощи Web Archive (ищите копии ДО 2013 года!). Тут вам на помощь придёт скрипт для языка Ruby wayback_machine_downloader. В крайнем случае можете попробовать сообщить автору сайта о планируемом восстановлении (чаще всего посредством электронной почты, указанной на сайте - лучше, если будет указан почтовый ящик вида [email protected], [email protected], так как другие ящики могут быть неактивны по причине "смерти" сервера или домена).
На некоторых сайтах могут возникнуть проблемы с определением кодировки (вплоть до того, что может отсутствовать специальный meta-тег). Если на сайте разные страницы используют разные кодировки, советуем перевести страницы в Windows-1251.
На многих сайтах narod.ru изначально была установлена кодировка Windows-1251, ныне отображающаяся как UTF-8. Скачайте утилиту Web-Sam: Unicode2Ansi для ускоренной смены кодировки.

Примеры meta-тега, содержащего информацию о используемой кодировке:
Также иногда могут скачиваться вместе с сайтом и директории с названиями типа "Gh5hNHdgvj5", которые тоже могут содержать рекламные скрипты, которые чаще всего имеют аналогичные названия. Удаляйте и их. НЕ ПЕРЕПУТАЙТЕ ИХ С НУЖНЫМИ ФАЙЛАМИ И ПАПКАМИ! После удаления зайдите на всякий случай в корзину и выполните поиск файлов с расширениями .htm, .html. Необходимые файлы восстановите.
И только после того, как проверены все внутренние ссылки, можно считать спасение сайта завершенным.
Виды поддоменов отреставрированных сайтов:
site.narodweb.ru - сайты с narod.ru
site-c.narodweb.ru - сайты с chat.ru
site-n.narodweb.ru - сайты с newmail.ru (nm.ru, hotmail.ru)
site-by.narodweb.ru - сайты с by.ru
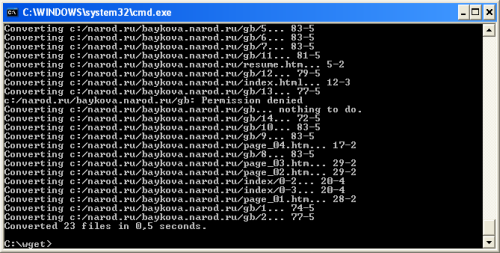
Скачивание сайта целиком на примере двух программ: Teleport Pro и Wget:
Teleport Pro
1. Скачиваем и устанавливаем программу.
2. Создаём новый проект.
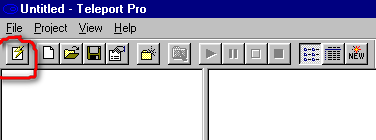
3. Выбираем пункт "Скачивать с сохранением структуры".
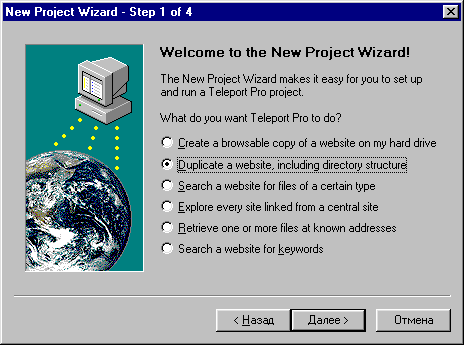
4. Вводим адрес скачиваемого сайта.
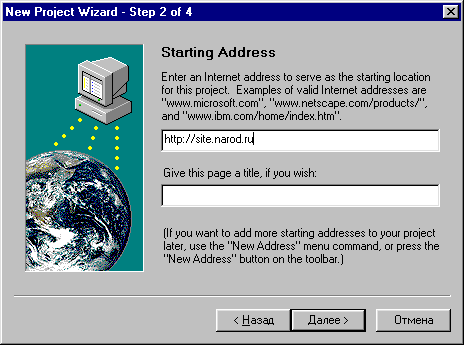
5. Скачиваем все доступные файлы сайта.
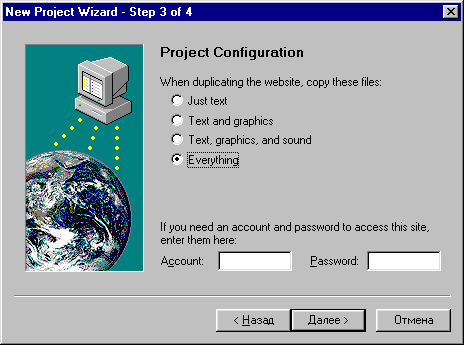
6. Нажимаем "Готово"
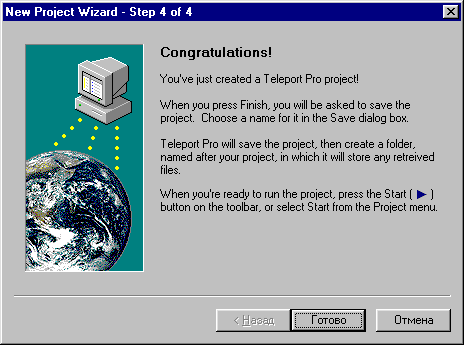
7. Запускаем скачивание сайта.
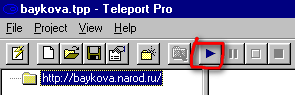
Wget
1. Скачиваем и распаковываем архив.
2. Нажимаем Пуск - Выполнить - cmd.
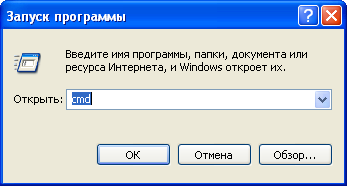
3. Рекомендуем вам следующие параметры:
-r - рекурсивная передача файлов
-l xxx - количество файлов, которое хотите скачать
-k - создание внутренних ссылок для просмотра сайта на ПК
-P c:/sites/ - директория, в которую нужно сохранить сайт
-erobots=off - игнорирование файла robots.txt
4. Набираем нужную команду с нужными параметрами.
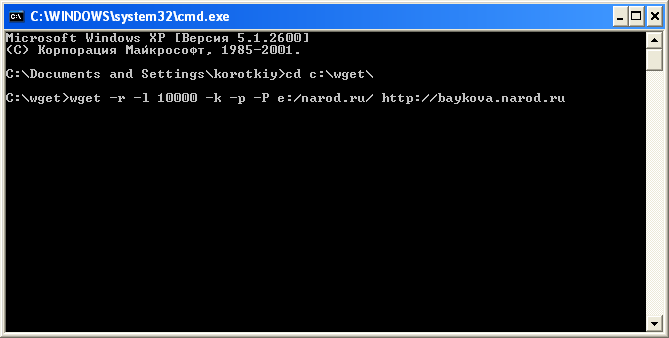
5. Скачиваем сайт.